
Ostinato goes Turbo at 100Gbps
Happy New Year!
In true geek fashion, I spent the Christmas holidays tinkering - this time on the Ostinato network traffic generator’s high-speed add-on - Turbo Transmit. And I’m happy to share that Ostinato Turbo can now generate 100Gbps!
What was the trick you ask?
Horizontal scaling - using multiple cores.
The scaling problem
The base Ostinato software can use a max of only one core per port to transmit packets. Trying to transmit packets from multiple cores to a single ethernet port runs into contention at the kernel, driver and NIC thus not delivering the desired performance increase. There wasn’t much Ostinato could do about this, but it’s something that needed to be solved at the lower layers.
NIC manufacturers know about this problem and when designing high-speed NICs - 10Gbps or higher, they introduced multiple TX and RX queues (or sometimes combined TX+RX queues) for each port e.g. here’s Intel 40G XL710 -
$ ethtool -l enp4s0f0np0
Channel parameters for enp4s0f0np0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 16
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 2
Once the hardware supported multiple queues, the Linux kernel and drivers were updated to utilize that.
Voila! No contention - as long as we use one CPU core per NIC queue!
We can now use multiple CPU cores independently.
Ostinato Turbo
The Ostinato Turbo add-on was architected to utilize multiple queues per port (and therefore multiple cores) from day one, but till now used only one core and one queue because as it turned out that was enough - thanks to the magic of AF_XDP fast path which delivered a whopping 20 million packets/sec with just a single core (for reference 10Gbps at 64 bytes is 14.8 Mpps). The catch - the NIC driver must support AF_XDP zero-copy which Intel and a few other NICs do.
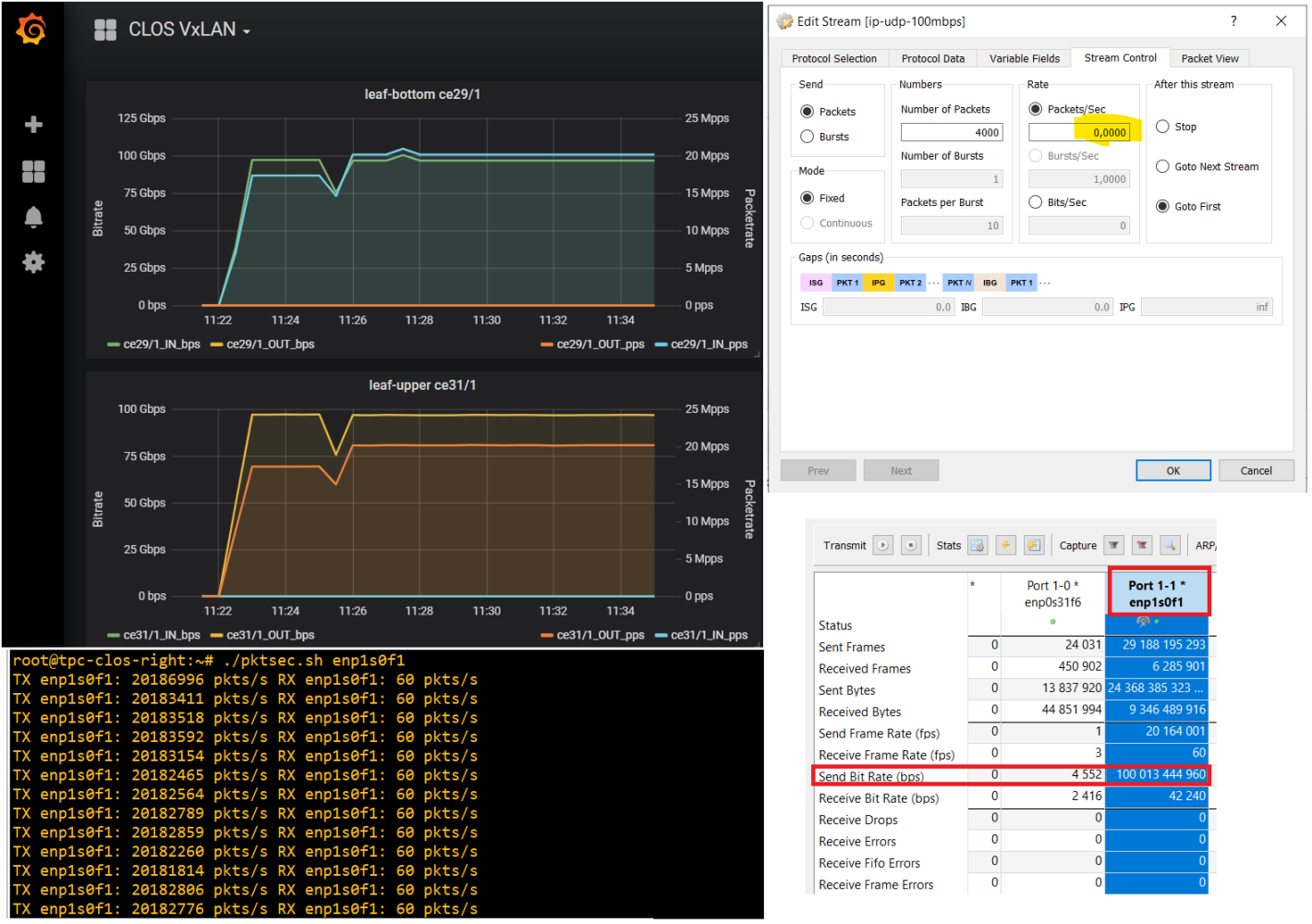
In November, a customer asked me if Ostinato could do 100Gbps and I told him Turbo could do 100Gbps at 600 byte packet sizes (or higher) on the Intel E810 NIC. How, you ask? Because 100Gbps at 600 bytes comes to 20 Mpps - our single core/queue limit!
The customer was ok with this and went ahead. Here’s a screenshot from their test -
At around the same time, another customer reached out and asked about 10Gbps on AWS/Azure. My tests on those platforms revealed that although both supported AF_XDP, but not zero-copy - the max single core performance was only about 1 million packets/sec. For 10Gbps that works out to a minimum packet size of 1230 bytes to achieve 10Gbps which was not acceptable to the customer.
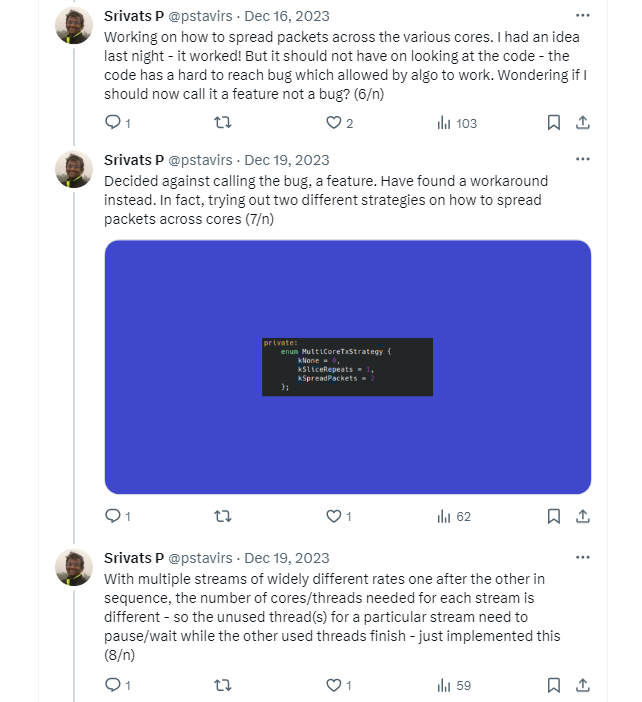
Going multi-core
It was time to extend Turbo to use multiple queues and cores - something I had designed-in but not implemented yet.
The first challenge was how to modify the highly-optimized and somewhat complex packet Tx code to utilize multiple cores - this took only a few days of experimenting.
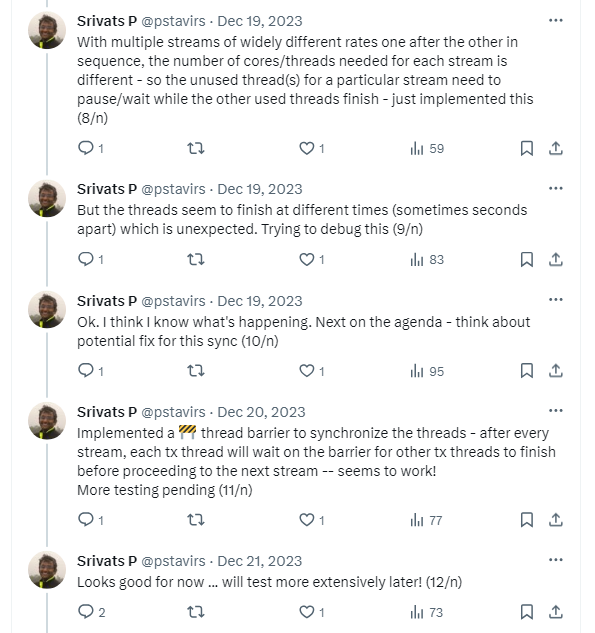
The second challenge was to sync the Tx across cores after each stream - implementing a thread barrier solved that problem.
The last big challenge was to ensure per-stream stats and latency/jitter work across cores - a challenge again because of the highly-optimized and complex code for the same.
Before Christmas eve I had all the core functionality working and the productivity continued post Christmas too – till unexpectedly, I had to take a few days off.
Getting back into the groove proved to be a bit of a challenge - having to update the turbo-tune bash script didn’t help (No, I don’t enjoy bash scripting - even with ChatGPT help!). I was distracted and procrastinating.

Once I got through that slump and I thought I’m almost done, I hit a pesky race condition for some cases. You know how much fun those are!
All in all, I got everything done in about 4 weeks - which I must admit I’m quite proud of and a testament to architecting Turbo right to make this multi-core work easy.
With these changes you need just 8 CPU cores to generate 100Gbps traffic at 64 bytes on a AF_XDP zero-copy supported NIC such as the Intel E810!
I posted almost-daily updates on a build-in-public Twitter thread all through those weeks - as you can see from the screenshots above. This is something I’ve been doing off late for all big and small Ostinato features and if you are interested in Ostinato development, you should follow me on Twitter.
10Gbps on the public cloud
The multi-core Turbo enables not just 100Gbps on physical NICs but also 10Gbps on AWS and Azure cloud VMs (Google Cloud should also work, but I haven’t got around to test on it yet).
Here are my results on a Azure cloud VM -
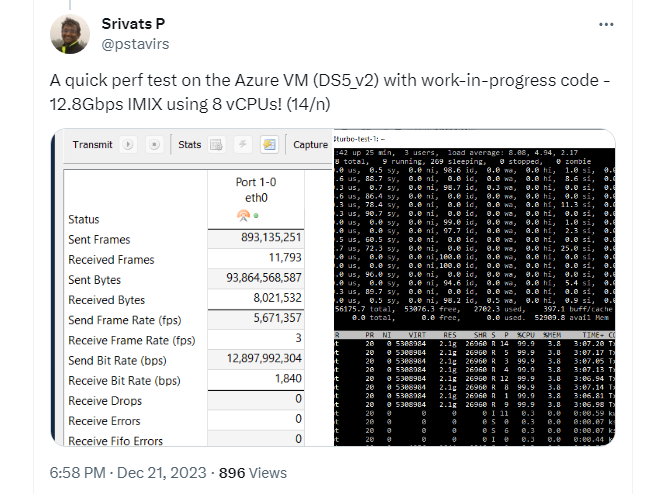
An important point to note about the cloud VMs is that all of them impose a aggregate bandwidth limit across all interfaces of the VM instance which is typically lower than the interface link speed. This bandwidth limit varies according to instance type, so you have to choose a VM/instance type accordingly!
Turbo System Requirements
With this newly acquired ability to scale TX across multiple CPU cores - the system requirements to run Turbo are much simpler, cheaper and accessible now - all you need is a NIC (or vNIC) that supports multiple queues and a multi-core CPU!
Adopt Ostinato Turbo today and save your team and your company a gazillion dollars in test equipment!
Questions? Let me know in the comments!
If you found this interesting, help me spread the word by sharing this article using the share buttons below!
For more Ostinato related content, subscribe for email updates.


Leave a Comment